
Plausibilitätsprüfung im PIM: Produktdaten automatisch prüfen und validieren
Die Plausibilitätsprüfung (auch als Plausibilitätskontrolle, Plausicheck oder CrossCheck bezeichnet) ist ein zentraler Bestandteil moderner Datenqualitätssysteme, automatisierter Datenlogik und der Datenverarbeitung im PIM. Sie sorgt dafür, dass Daten nicht nur vollständig, sondern auch logisch konsistent und fachlich korrekt sind.
Gerade im Product Information Management (PIM) entscheiden Plausibilitätsprüfungen darüber, ob Produktdaten zuverlässig, verkaufsfähig und systemübergreifend nutzbar sind.
👉 Plausibilitätsprüfungen sind damit ein zentraler Bestandteil strukturierter Produktdaten im PIM und tragen wesentlich zur Datenqualität und Konsistenz bei.
👉 Sie bilden gleichzeitig eine wichtige Grundlage für die Messung von Produktdatenqualität im PIM, etwa über KPIs und Data Quality Scores.
Was ist eine Plausibilitätsprüfung?
Eine Plausibilitätsprüfung ist eine Methode zur Überprüfung von Daten auf inhaltliche Konsistenz und logische Korrektheit. Dabei wird geprüft, ob Daten sinnvoll zusammenpassen und logisch nachvollziehbar sind – insbesondere im Product Information Management (PIM) – auch dann, wenn sie formal korrekt erscheinen.
👉 Beispiel:
Ein Campingplatz hat:
- einen Preis für Hunde hinterlegt
👉 Aber:
Sind Hunde überhaupt erlaubt?
→ Formal ist alles korrekt ausgefüllt.
→ Aber die Kombination ist nicht plausibel.
👉 Genau solche Widersprüche erkennt eine Plausibilitätsprüfung automatisch.
Im Unterschied zur reinen Validierung geht es nicht nur darum, ob ein Feld „richtig ausgefüllt“ ist, sondern ob:
- Werte zusammenpassen
- Abhängigkeiten eingehalten werden
- Kombinationen aus mehreren Attributen fachlich korrekt sind
Wie funktionieren Plausibilitätsprüfungen?
Plausibilitätsprüfungen basieren in der Regel auf vordefinierten Regeln (Business Rules), die Daten automatisch und in Echtzeit prüfen.
Typische Mechanismen:
- Wenn-Dann-Regeln
- Abhängigkeitsprüfungen zwischen Attributen
- Wertebereichsprüfungen
- Konsistenzprüfung über mehrere Felder hinweg
👉 In modernen Systemen wie einem PIM werden diese Regeln zentral definiert und automatisch ausgeführt – typischerweise durch eine Decision Engine im PIM. Mehr zur praktischen Umsetzung lesen Sie auf unserer Seite zur PIM‑Automatisierung.
Beispiele für Plausibilitätsprüfungen
Beispiel 1 – Abhängigkeiten und Konsistenz
Ein Campingplatz hat die Eigenschaft:
- Hunde erlaubt = „Ja“
👉 Dann gilt automatisch:
- Es muss entweder ein Preis für Hunde angegeben sein
- oder „Hunde kostenlos“ muss gesetzt sein
👉 Umgekehrt:
Wenn Hunde nicht erlaubt sind:
- darf kein Preis für Hunde hinterlegt sein
- und auch „kostenlos“ darf nicht gesetzt sein
👉 Und entscheidend:
Wenn sich der Status ändert (z. B. Hunde werden nicht mehr erlaubt), werden alle abhängigen Angaben automatisch angepasst oder entfernt.
👉 Diese Logik wird einmal definiert und wirkt automatisch bei jeder Änderung im gesamten Datenmodell.
👉 Ergebnis:
- keine widersprüchlichen Daten
- keine manuellen Korrekturen
- konsistente Produktdaten in allen Systemen
Beispiel 2 – UI-Steuerung durch Datenlogik
Plausibilitätsprüfungen können noch einen Schritt weiter gehen:
👉 Sie steuern direkt das Verhalten der Benutzeroberfläche.
Beispiel für eine Plausibiltätsprüfung:
Ein Campingplatz hat das Attribut:
- Hunde erlaubt
👉 Wenn „Hunde erlaubt = Ja“:
- wird das Feld „Preis für Hunde“ editierbar
- alternativ kann „Hunde kostenlos“ gesetzt werden
👉 Wenn „Hunde erlaubt = Nein“:
- werden diese Felder automatisch auf read-only gesetzt
- oder sind gar nicht sichtbar
👉 Ergebnis:
- fehlerhafte Eingaben sind gar nicht mehr möglich
- die Benutzeroberfläche bleibt klar und reduziert
- Nutzer werden automatisch durch die Logik geführt
💡 Wichtig:
Read-only Felder sind oft die bessere Wahl als komplettes Ausblenden
→ sie halten die Oberfläche ruhig und nachvollziehbar.
👉 Diese Logik basiert auf denselben Regeln, die auch für Plausibilitätsprüfungen gelten.
Sie wirken nicht nur im Hintergrund – sondern direkt im Interface.
Plausibilitätsprüfungen bedeuten nicht nur prüfen – sondern die Datenlogik aktiv steuern.
Daten werden nicht nur validiert, sondern automatisch in einen konsistenten Zustand gebracht – inklusive UI-Verhalten.
Weitere typische Plausibilitätsprüfungen
✅ Konsistenzprüfung
- Kategorie = „Buch“
- Mehrwertsteuer = 19 %
→ fachlich falsch
✅ Abhängigkeitsprüfung
- Gefahrenstoff vorhanden
→ Warnsymbol erforderlich
✅ Vollständigkeitsprüfung
- Produkt hat Preis, aber keine Kategorie
→ nicht freigabefähig
👉 Entscheidend:
Plausibilitätsprüfungen erkennen nicht nur Fehler – sie verhindern Inkonsistenzen.
Plausibilitätsprüfung vs. Datenvalidierung
Ein häufiger Fehler ist die Gleichsetzung beider Begriffe.
🔍 Datenvalidierung
- prüft Formalität
- z. B. Pflichtfelder, Datentypen
- „Ist das Feld korrekt ausgefüllt?“
🔍 Plausibilitätsprüfung
- prüft Logik und Zusammenhänge
- erkennt Widersprüche
- „Ist das Ergebnis sinnvoll?“
👉 Beispiel:
| Fall | Validierung | Plausibilität |
|---|---|---|
| Preis = „abc“ | ❌ Fehler | ❌ Fehler |
| Preis = „100 €“ | ✅ korrekt | ✅ plausibel |
| Buch + 19 % MwSt | ✅ korrekt | ❌ unplausibel |
👉 Fazit:
Validierung ist notwendig – Plausibilitätsprüfung ist entscheidend.
Warum Plausibilitätsprüfungen für Datenqualität entscheidend sind
Fehler entstehen selten durch fehlende Felder – sondern durch fehlende Logik.
Typische Probleme ohne Plausibilitätsprüfungen:
- inkonsistente Produktdaten
- falsche Attributkombinationen
- Fehler erst im Shop sichtbar
- hoher manueller Prüfaufwand
👉 Ergebnis:
- schlechtere Conversion
- mehr Rückfragen
- höhere Kosten
✅ Mit Plausibilitätsprüfungen:
- Daten werden automatisch geprüft
- Fehler entstehen gar nicht erst
- Abhängigkeiten werden systematisch berücksichtigt
- Datenqualität wird skalierbar
Automatisierte Plausibilitätsprüfungen im PIM
In modernen PIM-Systemen laufen Plausibilitätsprüfungen automatisch und in Echtzeit:
- bei der Dateneingabe
- bei jeder Änderung automatisch
- über das gesamte Datenmodell hinweg
Fachbereiche definieren Regeln z. B.:
((Pseudo-Code))
WENN Hunde erlaubt = JA
UND Preis für Hunde fehlt
UND Hunde kostenlos ≠ TRUE
DANN Fehler ausgeben
👉 Das System prüft diese Regel automatisch bei jedem Datensatz, bei jeder Dateneingabe, beim Speichern.
💡 Moderne Architektur
Typisch ist der Einsatz einer:
- Decision Engine
- Rules Engine
- zentralen Logikschicht
Diese sorgt dafür, dass:
- Regeln nur einmal definiert werden
- sie systemweit wirken
- Ergebnisse reproduzierbar bleiben
Plausibilitätsprüfungen automatisieren – warum Regeln besser sind als manuelle Checks
Viele Unternehmen nutzen noch:
- Excel-Listen
- manuelle Prüfprozesse
- implizites Wissen im Team
👉 Problem:
- Fehler werden spät erkannt
- Wissen ist nicht systematisiert
- Prozesse skalieren nicht
✅ Regelbasierte Plausibilitätsprüfungen:
- laufen automatisch
- sind nachvollziehbar
- sind jederzeit anpassbar
- reduzieren manuellen Aufwand drastisch
Plausibilitätsprüfungen im PIM sichtbar und steuerbar machen
Plausibilitätsprüfungen wirken im Hintergrund – werden aber im System klar sichtbar gemacht.
👉 Ziel ist es, Fehler nicht nur zu erkennen, sondern gezielt auffindbar und bearbeitbar zu machen.
✅ 1. Direkte Anzeige am Attribut
Fehler werden direkt dort angezeigt, wo sie entstehen:
- am jeweiligen Attribut im Datensatz
- visuell hervorgehoben
- mit Hinweis auf die konkrete Regel
👉 Der Nutzer erkennt sofort:
- welches Feld betroffen ist
- warum ein Fehler vorliegt

✅ 2. Zentrale Fehlerübersicht im Datensatz
Für jeden Datensatz steht eine vollständige Fehlerliste zur Verfügung:
- alle Plausibilitätsprüfungen werden in einem Panel angezeigt
- Fehler sind klickbar → direkte Navigation zum betroffenen Feld
👉 Zusätzlich werden vier Stufen unterschieden:
- Info → Hinweis, kein Eingriff erforderlich
- Warning → potenzielles Problem
- CrossCheck → Hinweis auf widersprüchliche oder abweichende Daten
- Error → kritischer Fehler
👉 Verhalten:
- Error → Speichern wird verhindert
- Info / Warning / CrossCheck → Speichern bleibt möglich
👉 Damit lässt sich genau steuern:
- welche Regeln strikt sind
- und welche unterstützend wirken

✅ 3. Fehler gezielt suchen und kombinieren
Plausibilitätsprüfungen sind nicht nur sichtbar, sondern auch auswertbar.
👉 Nutzer können gezielt nach Fehlern suchen:
- alle Datensätze mit bestimmten Fehlern anzeigen
- Fehler mit anderen Kriterien kombinieren
👉 Beispiele:
- alle fehlerhaften Artikel, die heute angelegt wurden
- alle fehlerhaften Produkte in Kategorie „Zangen“
- alle Datensätze, deren Artikelnummer mit „03“ beginnt
👉 Ergebnis:
- Fehler können systematisch bearbeitet werden
- auch große Datenbestände bleiben kontrollierbar
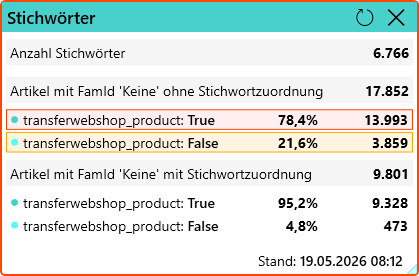
✅ 4. Echtzeit-Dashboard mit Fehlerübersicht
Zusätzlich steht ein Dashboard mit aggregierten Fehlern zur Verfügung:
- Darstellung über Kacheln
- automatische Aktualisierung alle paar Minuten
- basierend auf definierten Filterregeln
👉 Jede Kachel zeigt z. B.:
- Anzahl fehlerhafter Datensätze
- bestimmte Fehlerklassen
- definierte Qualitätsbereiche
👉 Diese Kacheln sind direkt interaktiv:
- Klick führt zur gefilterten Datensatzliste
- Fehler können sofort bearbeitet werden
🔥 Ergebnis
👉 Plausibilitätsprüfungen werden damit nicht nur ausgeführt, sondern:
✅ sichtbar
✅ navigierbar
✅ priorisierbar
✅ systemweit steuerbar
👉 Datenqualität wird dadurch kein Kontrollaufwand mehr – sondern ein steuerbarer Prozess.
Fazit – Plausibilitätsprüfung als Schlüssel zur Datenqualität
Plausibilitätsprüfungen sind kein optionales Feature, sondern ein zentraler Bestandteil moderner Datenarchitekturen.
👉 Sie sorgen dafür, dass Daten:
- konsistent
- logisch korrekt
- zuverlässig
- systemübergreifend nutzbar sind
🚀 Nächster Schritt
Wenn Sie Plausibilitätsprüfungen nicht nur dokumentieren, sondern automatisiert und systemweit umsetzen möchten:
👉 Erfahren Sie, wie Plausibilitätsprüfungen mit einer Decision Engine im PIM automatisch gesteuert und skaliert werden.