
Regelbasierte Datenlogik im PIM – wie Entscheidungen automatisiert entstehen
Datenqualität entsteht nicht durch vollständige Daten – sondern durch die richtige Logik.
In modernen PIM-Systemen (Product Information Management) geht es nicht nur darum, Daten zu speichern, sondern sie konsistent, korrekt und systemübergreifend nutzbar zu machen. Entscheidend dafür ist die zugrunde liegende Datenlogik.
Regelbasierte Datenlogik sorgt dafür, dass Daten nicht isoliert betrachtet werden, sondern in Abhängigkeiten und Zusammenhängen verarbeitet werden.
Warum Datenqualität allein nicht ausreicht
Viele Unternehmen setzen auf:
- Pflichtfelder
- Validierungen
- manuelle Prüfprozesse
👉 Diese stellen sicher, dass Daten vorhanden sind – aber nicht, dass sie inhaltlich zusammenpassen.
Typische Probleme:
- widersprüchliche Attributkombinationen
- fehlende Abhängigkeiten
- inkonsistente Produktdaten
👉 Die Ursache ist fast immer dieselbe:
Es fehlt eine zentrale Datenlogik.
Was ist regelbasierte Datenlogik im PIM?
Regelbasierte Datenlogik beschreibt die Fähigkeit eines Systems, Daten anhand definierter Regeln automatisch zu prüfen, zu steuern und zu verarbeiten.
👉 Dabei geht es nicht nur um Validierung, sondern um:
- Abhängigkeiten zwischen Attributen
- fachliche Konsistenz
- automatisierte Entscheidungen
- dynamische Anpassung von Daten
👉 Ziel:
- Daten sollen sich korrekt verhalten
- nicht manuell korrigiert werden müssen
Wie Datenlogik im PIM umgesetzt wird
In modernen Systemen basiert Datenlogik auf:
- Wenn-Dann-Regeln
- Attribut-Abhängigkeiten
- Entscheidungsmodellen
- zentral definierten Logikschichten
👉 Diese Regeln wirken:
- in Echtzeit
- bei jeder Änderung
- über das gesamte Datenmodell hinweg
💡 Wichtig:
Die zugrunde liegende Logik wird in der Regel durch eine zentrale Entscheidungsinstanz gesteuert – in Contene in Form einer 👉 Decision Engine.
Sie sorgt dafür, dass Regeln nicht isoliert wirken, sondern systemweit angewendet und konsistent ausgeführt werden.
Wie regelbasierte Datenlogik im PIM sichtbar wird
Regelbasierte Datenlogik wirkt im Hintergrund – ihre Auswirkungen werden jedoch im System sichtbar.
👉 Entscheidend ist:
Nicht die Anzeige selbst ist die Logik, sondern die Logik bestimmt, wann und warum etwas sichtbar wird.
✅ Die Grundlage: zentrale Regeln und Abhängigkeiten
In einem PIM mit regelbasierter Datenlogik wird definiert:
- welche Werte erlaubt sind
- welche Attribute voneinander abhängen
- welche Kombinationen ausgeschlossen sind
- und unter welchen Bedingungen ein Zustand als Fehler gilt
👉 Diese Regeln werden einmal zentral festgelegt und wirken systemweit.
Jede Änderung an einem Datensatz wird automatisch gegen diese Logik geprüft – unabhängig davon, wo sie entsteht.
✅ Vom Regelwerk zur sichtbaren Auswirkung
Die visuelle Darstellung von Hinweisen und Fehlern ist kein separates Feature.
👉 Sie ist das direkte Ergebnis der zugrunde liegenden Datenlogik.
Dadurch kann das System:
- Abweichungen auf Attributsebene sichtbar machen
- den Zustand eines gesamten Datensatzes bewerten
- unterschiedliche Fehlerstufen unterscheiden
- und Datenqualität konsistent steuern
✅ Unterschiedliche Bewertungen statt einfacher Fehlerlogik
Regelbasierte Datenlogik unterscheidet nicht nur zwischen „richtig“ und „falsch“.
👉 Stattdessen werden Zustände differenziert bewertet:
- Hinweise bei optionalen Verbesserungen
- Warnungen bei potenziellen Problemen
- Abweichungen bei widersprüchlichen Daten
- Fehler bei kritischen Regelverstößen
👉 Diese Differenzierung entsteht nicht in der Anzeige –
👉 sondern durch die hinterlegte Entscheidungslogik.
✅ Systemweite Steuerung statt einzelner Prüfungen
Da alle Prüfungen auf derselben Datenlogik basieren, können Ergebnisse systemweit genutzt werden:
- zur Bewertung einzelner Datensätze
- zur Steuerung von Prozessen
- zur Priorisierung von Datenqualität
👉 Damit wird Datenprüfung nicht zu einer isolierten Funktion,
sondern zu einem integralen Bestandteil der gesamten Datenlogik und Verarbeitung.
👉 Die visuelle Darstellung von Fehlern ist nicht die Ursache – sondern das Ergebnis einer zentral gesteuerten Datenlogik.
👉 Erst durch diese regelbasierte Datenlogik im PIM wird es möglich, Daten nicht nur zu prüfen, sondern konsistent zu steuern.
Beispiel: GHS-Daten logisch steuern
Ein typischer Anwendungsfall für regelbasierte Datenlogik ist die Verarbeitung von Gefahrstoffdaten (GHS).
1. Ausgangssituation
Ein Produkt wird mit GHS-Piktogrammen versehen.
👉 Beispiel:
- GHS02 – Flamme
- GHS05 – Ätzwirkung

2. Regel greift automatisch
Sobald ein Piktogramm gesetzt wird, gilt:
👉 Es muss ein Signalwort gewählt werden
(z. B. „Gefahr“ oder „Achtung“)
3. Fehlende Eingaben werden erkannt
Wenn kein Signalwort gesetzt ist:
👉 wird ein Regelverstoß erkannt und als Fehler angezeigt
→ Nutzer wird gezielt zur korrekten Eingabe geführt


4. Abhängigkeiten werden erzwungen
Nach Auswahl des Signalworts:
👉 können passende GHS-Referenzen ausgewählt werden
→ z. B. konkrete Gefahrenhinweise
5. Ergebnis: Daten werden automatisch erzeugt
Basierend auf den gewählten Werten generiert das System:
- Signalwort („Gefahr“)
- strukturierte Gefahrenhinweise
- vollständige GHS-Texte
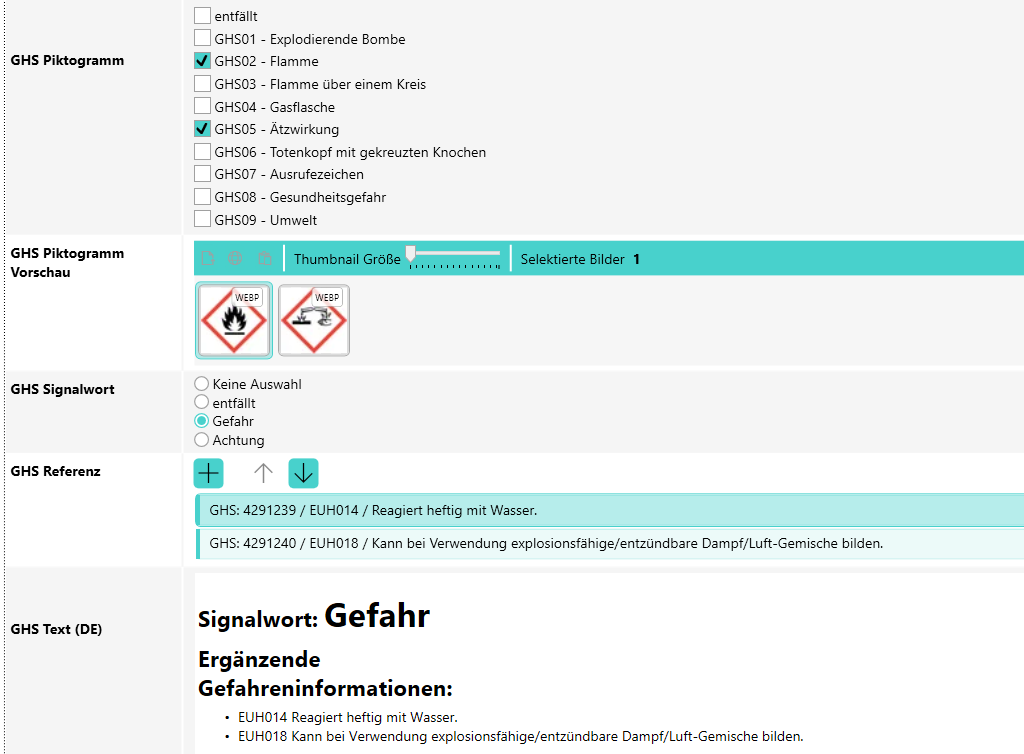
👉 Ergebnis:
- keine inkonsistenten Daten
- kein manueller Aufwand
- standardisierte Ausgabe
👉 Entscheidend:
Alle Schritte – von der Eingabe bis zum fertigen Text –
werden durch eine zentrale Datenlogik gesteuert.
Was sind Plausibilitätschecks?
Die gezeigten Beispiele basieren auf konkreten Regeln und Abhängigkeiten, die im System definiert werden.
In Contene werden solche Logiken als Plausibilitätsprüfung umgesetzt.
👉 Plausibilitätschecks sind regelbasierte Mechanismen, die Daten nicht nur prüfen, sondern aktiv steuern.
Sie definieren:
- welche Werte erlaubt sind
- welche Abhängigkeiten bestehen
- welche Kombinationen logisch korrekt sind
- welche Aktionen automatisch ausgelöst werden
👉 Im Unterschied zu klassischen Validierungen:
Plausibilitätschecks…
- erkennen nicht nur Fehler
- verhindern Inkonsistenzen
- führen den Nutzer durch den Prozess
- erzeugen konsistente Ergebnisse
Beispiel (GHS)
Wenn ein Piktogramm gesetzt wird:
- wird ein Signalwort erforderlich
- werden Referenzen erwartet
- wird ein strukturierter Text erzeugt
👉 Alle diese Schritte sind Teil eines einzigen Plausibilitätschecks.
Entscheidender Unterschied
Plausibilitätschecks wirken nicht isoliert, sondern systemweit.
Das bedeutet:
- jede Änderung wird geprüft
- Abhängigkeiten greifen sofort
- Daten werden automatisch angepasst
👉 Sie sind damit die operative Umsetzung regelbasierter Datenlogik im PIM.
Wie Regeln in der Praxis definiert werden
Ein entscheidender Vorteil moderner Systeme ist die zentrale Definition von Regeln.
Typischerweise werden:
- Feldabhängigkeiten
- Bedingungen
- Fehlermeldungen
- Ableitungslogiken
zentral verwaltet.
👉 Fachbereiche können diese Regeln selbst definieren, anpassen und sofort im System wirksam machen – ohne Entwicklungsaufwand.
Beispiel für die Regeldefinition von Plausibilitätschecks

Grün markiert sind die referenzierten Attribute, blau die Inhalte und orange die logischen Bedingungen.
Die daraus entstehenden Regeln werden automatisch im System ausgeführt und direkt in der Benutzeroberfläche angewendet.
👉 Diese Regel wird:
- automatisch ausgeführt
- auf alle relevanten Daten angewendet
- jederzeit anpassbar
Der entscheidende Unterschied liegt nicht nur darin, dass Regeln definiert werden – sondern wie einfach sie angepasst werden können.
👉 In Contene werden Plausibilitätschecks zentral in Excel definiert und gepflegt.
Das bedeutet:
- Fachbereiche können Regeln selbst ändern
- Anpassungen sind sofort wirksam
- keine Entwicklungszyklen erforderlich
- keine Abhängigkeit von IT oder externen Ressourcen
👉 Der Effekt im Alltag:
Ändert sich eine fachliche Regel – z. B. eine neue GHS-Anforderung oder eine geänderte Attributlogik – kann diese direkt angepasst werden.
- Ohne Tickets.
- Ohne Release-Zyklen.
- Ohne Systemeingriffe.
👉 Datenlogik wird damit von einem technischen Thema zu einer steuerbaren Fachlogik.
💡 Genau hier liegt der Unterschied zu klassischen Systemen:
Dort müssen Regeln entwickelt oder konfiguriert werden.
👉 In Contene werden sie gepflegt.
Warum regelbasierte Datenlogik entscheidend ist
Ohne zentrale Datenlogik entstehen:
- inkonsistente Datensätze
- manuelle Korrekturen
- Fehler in Downstream-Systemen
- hoher Pflegeaufwand
✅ Mit regelbasierter Datenlogik:
- Daten bleiben konsistent
- Abhängigkeiten werden automatisch berücksichtigt
- Prozesse werden skalierbar
- Fehler werden vermieden
👉 Das Ergebnis:
- bessere Datenqualität
- geringerer Aufwand
- schnellere Prozesse
Fazit – Datenlogik als Grundlage moderner PIM-Systeme
Regelbasierte Datenlogik ist die Grundlage dafür, dass Daten nicht nur erfasst, sondern aktiv gesteuert werden können.
👉 Sie sorgt dafür, dass:
- Daten logisch zusammenpassen
- Systeme konsistent bleiben
- Inhalte automatisch entstehen
👉 Plausibilitätschecks sind dabei die zentrale Mechanik, mit der diese Logik umgesetzt wird.
Nächster Schritt
Wenn Sie verstehen möchten, wie diese Datenlogik systemweit gesteuert und skaliert wird:
👉 Erfahren Sie, wie eine Decision Engine im PIM diese Regeln zentral umsetzt.