
Produktdatenqualität im PIM messen: KPIs, Data Quality Score und systematische Bewertung
Produktdatenqualität im PIM lässt sich nur dann gezielt verbessern, wenn sie messbar wird.
In vielen Unternehmen erfolgt dies über KPIs und einen Data Quality Score, der den Zustand von Produktdaten objektiv beschreibt.
Dabei geht es nicht nur darum, Daten zu erfassen oder zu prüfen – sondern ihren Zustand systematisch zu bewerten und kontinuierlich zu steuern.
👉 Genau hier setzt die Messung von Produktdatenqualität an.
Warum Produktdatenqualität gemessen werden muss
Schlechte Produktdatenqualität wirkt sich nicht nur intern aus, sondern hat direkte wirtschaftliche Konsequenzen:
- höhere Retourenquoten
- geringere Konversionsraten
- sinkendes Kundenvertrauen
- steigender Pflege- und Abstimmungsaufwand
Ohne Messung bleibt unklar:
- wie gut die Daten tatsächlich sind
- wo konkret Probleme liegen
- welche Maßnahmen Priorität haben
👉 Erst durch klare Kennzahlen wird Datenqualität objektiv bewertbar.
Einordnung: Produktdatenqualität im PIM-Kontext
Der Begriff Produktdatenqualität wird in unterschiedlichen Kontexten verwendet.
Im Engineering- oder PLM-Umfeld bezieht er sich häufig auf technische Produktdaten wie CAD-Modelle oder Fertigungsinformationen.
👉 Im Kontext von PIM und E‑Commerce hingegen beschreibt Produktdatenqualität die Qualität von Produktinformationen für Vertrieb, Marketing und digitale Kanäle.
Welche KPIs zur Produktdatenqualität verwendet werden
Produktdatenqualität wird anhand definierter KPIs bewertet.
Typische KPI-Dimensionen sind:
- Vollständigkeit
- Korrektheit
- Konsistenz
- Aktualität
- Eindeutigkeit
Je nach Anwendungsfall kommen weitere KPI-Dimensionen hinzu:
- Relevanz: Passen Inhalte zum Nutzungskontext?
- Validität: Entsprechen Werte definierten Formaten und Regeln?
- Compliance: Werden regulatorische Anforderungen erfüllt?
👉 Diese KPIs beschreiben den Zustand der Daten – entscheidend ist jedoch, wie sie praktisch bewertet und kombiniert werden.
Warum Vollständigkeit als KPI allein nicht ausreicht
Die Messung von Vollständigkeit ist einfach:
Ein Attribut ist entweder gefüllt oder nicht.
Doch:
👉 Vollständige Daten sind nicht automatisch qualitativ hochwertige Daten.
Ein Feld kann:
- formal gefüllt
- aber fachlich falsch
- widersprüchlich
- oder unplausibel sein
👉 Dadurch entsteht ein KPI-Wert ohne echte Aussagekraft.
Korrektheit und Plausibilitätsprüfung
Neben Vollständigkeit spielen qualitative KPIs eine zentrale Rolle.
Plausibilitätsprüfungen im PIM erkennen zum Beispiel:
- widersprüchliche Attributkombinationen
- unrealistische Wertebereiche
- fehlende fachliche Abhängigkeiten
👉 Wichtig:
Plausibilitätsprüfungen können Korrektheit nicht vollständig garantieren, liefern aber entscheidende Hinweise auf Qualität, Konsistenz und fachliche Logik.
Sie ersetzen keine fachliche Wahrheit, machen jedoch Abweichungen und Risiken sichtbar.
👉 Produktdatenqualität wird damit nicht nur gemessen, sondern fachlich bewertet.
Konkrete Beispiele finden Sie auf der Seite Typische Anwendungsfälle für Plausibilitätsprüfungen im PIM.
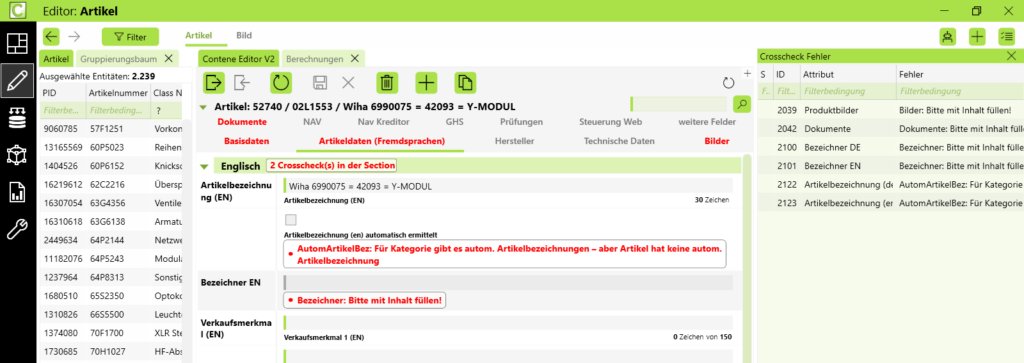
Wie KPIs im PIM konkret bewertet werden
In der Praxis werden KPIs in kombinierte Bewertungsmodelle überführt, die häufig auf regelbasierter Datenlogik basieren.
Typische Bestandteile:
- gewichtete Pflichtfelder
- Medienanforderungen (z. B. Bilder, Dokumente)
- Vollständigkeitsregeln
- Plausibilitätsprüfungen
- kontextabhängige Anforderungen
👉 Entscheidend:
Nicht jeder KPI gilt für jeden Artikel.
Beispiel:
- Sicherheitsdatenblätter sind nur für Gefahrgutartikel relevant
- Für andere Artikel wird dieser KPI nicht berücksichtigt
👉 Dadurch bleibt die Bewertung fachlich korrekt.
Typische KPIs und Scoring-Modelle zur Messung der Produktdatenqualität
Die Bewertung von Produktdatenqualität erfolgt in der Praxis häufig über gewichtete KPIs, die zu einem Gesamtwert zusammengeführt werden.
Ein typisches Modell kombiniert mehrere Dimensionen:
- Vollständigkeit (Completeness): Sind alle relevanten Attribute gepflegt?
- Korrektheit (Accuracy): Entsprechen die Daten den tatsächlichen Eigenschaften?
- Konsistenz (Consistency): Sind die Daten widerspruchsfrei?
- Aktualität (Timeliness): Wie aktuell sind die Informationen?
Diese Dimensionen werden gewichtet und zu einem Data Quality Score zusammengeführt:
Completeness: 40%
Accuracy: 30%
Consistency: 20%
Timeliness: 10%🔢 Beispiel für eine einfache Berechnung
Ein Unternehmen hat 100 Produkte:
- 92 vollständig gepflegt → 92 % Completeness
- 85 korrekt → 85 % Accuracy
- 90 konsistent → 90 % Consistency
- 80 aktuell → 80 % Timeliness
Daraus ergibt sich ein gewichteter Gesamtwert:
(92×0,4) + (85×0,3) + (90×0,2) + (80×0,1) = 88,3🔥Data Quality Score: 88,3 von 100
📊 Interpretation des Scores
Der berechnete Wert ermöglicht eine klare Einordnung:
- 0–50 Punkte → kritische Datenqualität
- 50–80 Punkte → solide, aber optimierungsbedürftig
- 80–100 Punkte → hohe Datenqualität
👉 Dadurch wird Produktdatenqualität nicht nur messbar, sondern auch steuerbar.
Data Quality Score: KPI-Aggregation zum Systemzustand
Ein Data Quality Score ist eine aggregierte Kennzahl, die mehrere KPIs nach definierten Regeln und Gewichtungen zusammenführt.
Aus den KPI-Bewertungen entsteht:
- eine Gesamtpunktzahl
- die Ableitung eines Datenzustands
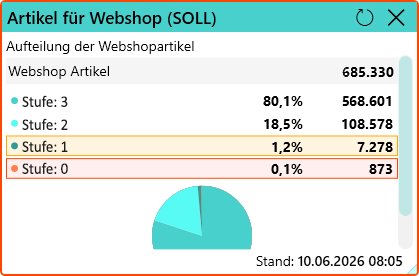
Ein mögliches Zustandsmodell könnte wie folgt aussehen:
- Stufe 0: unvollständig (nicht veröffentlichungsfähig)
- Stufe 1: teilweise gepflegt (nicht veröffentlichungsfähig)
- Stufe 2: weitgehend vollständig (veröffentlichungsfähig)
- Stufe 3: vollständig (veröffentlichungsfähig)
👉 Der Score übersetzt KPI-Werte in einen operativen Zustand.
Diese KPIs bilden die Grundlage dafür, Produktdatenqualität im PIM systematisch zu verbessern.
Messung erfolgt kontinuierlich – nicht nachgelagert
In vielen Systemen werden KPIs periodisch berechnet.
In modernen PIM-Ansätzen erfolgt die Bewertung typischerweise:
- ereignisbasiert bei Änderungen
- automatisch im Hintergrund
👉 Viele Systeme aktualisieren KPI-Werte kontinuierlich, anstatt ausschließlich auf periodische Batch-Läufe zu setzen.
Keine Blackbox: KPIs und Scores sind nachvollziehbar
Ein häufiges Problem klassischer KPI-Modelle ist fehlende Transparenz.
👉 Ergebnisse werden angezeigt, aber nicht erklärt.
In einem regelbasierten Modell ist die Bewertung nachvollziehbar und eng mit automatischer Datenvalidierung verknüpft.
- jede KPI-Regel ist sichtbar
- Soll- und Ist-Werte werden gegenübergestellt
- konkrete Inhalte fließen in die Bewertung ein
- Abweichungen sind direkt erklärbar
👉 Der Data Quality Score ist damit vollständig nachvollziehbar.

Von KPIs zur Steuerung
Der entscheidende Mehrwert entsteht durch die Nutzung der KPI-Ergebnisse:
- KPIs zeigen Probleme
- Bewertungen priorisieren Maßnahmen
- Systemlogik steuert Prozesse
Beispielsweise:
- Freigabe für den Webshop
- Export in Kanäle
- Weiterverarbeitung in Systemen
👉 KPIs werden damit operativ wirksam. Die Systemlogik basiert häufig auf regelbasierter PIM Automatisierung, die Bewertungen direkt in Prozesse überführt.
Dashboard: KPIs als Steuerungsinstrument
Die KPI-Bewertung wird in Dashboards sichtbar:
- Verteilung nach Datenqualitätsstufen
- Anteil veröffentlichungsfähiger Artikel
- Identifikation von Handlungsbedarf
👉 zentrale Funktion:
- Klick auf KPI
- Anzeige der betroffenen Artikel
- direkte Bearbeitung
👉 KPIs werden nicht nur berichtet, sondern genutzt.
Warum KPI-Modelle ohne Prozessintegration oft schwer skalieren
Viele KPI-Modelle bleiben in der Praxis isoliert.
Sie werden definiert, gemessen und ausgewertet – sind jedoch nicht direkt mit operativen Prozessen verknüpft.
Typische Folgen sind:
- hoher Implementierungsaufwand
- IT-Abhängigkeit bei Anpassungen
- zeitverzögerte Auswertungen
- keine direkte operative Nutzung
KPIs schaffen in diesen Fällen zwar Transparenz, führen jedoch nicht automatisch zu Verbesserungen oder operativen Entscheidungen.
👉 Entscheidend ist daher nicht das KPI-Modell selbst, sondern seine Integration in Prozesse und Systemlogik.
Entscheidender Unterschied: System statt Reporting
In einem integrierten PIM-Ansatz:
- KPI-Regeln sind Teil des Systems
- Bewertungen erfolgen kontinuierlich
- Zustände entstehen automatisch
- Entscheidungen werden direkt gesteuert
👉 Datenqualität ist Teil der Systemlogik.
Datenqualität ist nur ein Teil der Entscheidung
KPIs und Scores sind Grundlage – aber nicht die Entscheidung selbst.
Weitere Faktoren:
- fachlicher Status
- Verkaufbarkeit
- logistische Bedingungen
- Artikelabhängigkeiten
👉 Daraus entsteht eine übergeordnete Entscheidungslogik.
Zusammenhang zur Veröffentlichungsfähigkeit
Ein Artikel ist nur dann veröffentlichungsfähig, wenn:
- seine KPI-Bewertung ausreichend ist
- alle weiteren Bedingungen erfüllt sind
- der Zustand stabil bleibt
👉 Veröffentlichung ist ein berechneter Zustand.
👉 Mehr dazu im Whitepaper zur Veröffentlichungsfähigkeit im PIM
FAQ: Produktdatenqualität messen
Was ist ein Data Quality Score?
Ein Data Quality Score ist eine Kennzahl, die mehrere KPIs zur Datenqualität in einem Wert zusammenfasst und daraus einen Datenzustand ableitet.
Welche KPIs messen Produktdatenqualität?
Typische KPIs sind Vollständigkeit, Konsistenz, Aktualität, Korrektheit, Validität und Compliance, ergänzt durch kontextabhängige Kriterien.
Warum reicht Vollständigkeit allein nicht aus?
Ein gefülltes Feld kann dennoch falsch oder unplausibel sein. Erst durch qualitative Prüfungen entsteht eine belastbare Bewertung.
Wie wird Produktdatenqualität im PIM automatisch bewertet?
Durch Regelwerke und KPI-Modelle, die bei Änderungen automatisch angewendet werden und daraus Scores, Zustände und Entscheidungen ableiten.
Fazit
Produktdatenqualität im PIM zu messen bedeutet:
- KPIs definieren
- Bewertungen automatisieren
- Zustände berechnen
- Entscheidungen ermöglichen
👉 Datenqualität wird nicht nur gemessen, sondern systemisch gesteuert.