
Produktdatenqualität im PIM: Definition, Probleme und systematische Verbesserung
Produktdatenqualität im PIM beschreibt den Zustand und die Verlässlichkeit aller produktbezogenen Informationen.
Dazu gehören insbesondere:
- Vollständigkeit von Attributen und Inhalten
- fachliche Korrektheit der Daten
- Konsistenz über alle Systeme und Kanäle hinweg
- Aktualität und Pflegezustand
- Einhaltung regulatorischer Anforderungen
In klassischen Systemen wird Produktdatenqualität häufig manuell geprüft.
Im PIM von Contene entsteht sie dagegen systematisch – durch Entscheidungslogik und automatisierte Validierung.
👉 Dieser Ansatz ist ein zentraler Bestandteil der PIM‑Automatisierung und zeigt, wie fachliche Entscheidungen im PIM systematisch modelliert und automatisiert werden.
Produktdaten entscheiden darüber, ob Produkte gefunden, verstanden und gekauft werden. Schlechte Datenqualität führt zu schlechter Auffindbarkeit, unklaren Informationen und letztlich zu geringerer Conversion im Webshop.
Viele Unternehmen kämpfen dabei mit denselben Problemen: unvollständige Daten, widersprüchliche Angaben oder manuelle Pflege ohne klare Regeln.
👉 Wie lässt sich Datenqualität im PIM systematisch verbessern – nicht nur punktuell, sondern dauerhaft?
Welche Kriterien bestimmen Produktdatenqualität im PIM?
Produktdatenqualität wird häufig anhand zentraler Kriterien bewertet:
- Vollständigkeit
- Korrektheit
- Konsistenz
- Aktualität
- Konformität
Diese Kriterien beschreiben den Zustand der Daten – sie erklären jedoch nicht, wie dieser Zustand zuverlässig entsteht.
👉 Wie Produktdatenqualität im PIM tatsächlich gemessen und bewertet wird, zeigt der Beitrag zur Produktdatenqualität im PIM messen.
Genau hier liegt der entscheidende Unterschied: Klassische Systeme prüfen diese Kriterien nachgelagert.
Ein entscheidungsbasiertes PIM erzeugt Produktdatenqualität systematisch – durch Regeln, Bewertungen und automatische Zustände.
Typische Probleme bei der Produktdatenqualität im PIM
In der Praxis entstehen Probleme selten durch einzelne Fehler, sondern durch strukturelle Schwächen im Umgang mit Produktdaten.
- fehlerhafte oder widersprüchliche Attribute
- fehlende Produktbeschreibungen oder Bilder
- uneinheitliche Daten aus verschiedenen Systemen (z. B. ERP vs. PIM)
- unvollständige regulatorische Angaben
- manuelle Pflege ohne klare Regeln
👉 Die Folge:
- Produkte sind schwer auffindbar
- Kunden verstehen das Produkt nicht vollständig
- Fehler gelangen in den Webshop oder in andere Kanäle
- der Pflegeaufwand steigt kontinuierlich
Warum klassische Datenpflege nicht ausreicht
In vielen Systemen wird Datenqualität als reine Pflegeaufgabe verstanden:
- Attribute werden manuell befüllt
- Texte werden einzeln kontrolliert
- Fehler werden nur entdeckt, wenn jemand sie sieht
Dieses Vorgehen hat zwei grundlegende Probleme:
- es skaliert nicht bei großen Datenmengen
- es stellt keine konsistente Qualität sicher
👉 Datenqualität entsteht so eher zufällig als systematisch.
Wie lässt sich Datenqualität im PIM verbessern?
Datenqualität im PIM lässt sich nur dann nachhaltig verbessern, wenn sie nicht manuell kontrolliert, sondern systemisch erzeugt wird. Eine zentrale Voraussetzung dafür ist, dass der Zustand der Daten überhaupt messbar ist – beispielsweise über KPIs und Data Quality Scores.
Entscheidend sind:
- automatisierte Validierung statt manueller Prüfung
- klare Regeln für Datenbeziehungen
- kontinuierliche Bewertung von Produktzuständen
- automatische Ableitung von Datenqualitätszuständen
Ein modernes PIM fungiert dabei als zentrale Datenbasis („Single Source of Truth“), in der alle Produktinformationen zusammenlaufen und bewertet werden.
Der entscheidende Unterschied: Datenqualität als System
Der systemische Ansatz verändert nicht nur, wie Daten geprüft werden, sondern wie sie entstehen.
Im Gegensatz zu manuellen Prozessen bedeutet das:
- Daten werden nicht punktuell kontrolliert, sondern kontinuierlich bewertet
- Abhängigkeiten zwischen Attributen werden automatisch berücksichtigt
- Zustände wie „vollständig“ oder „veröffentlichungsfähig“ entstehen aus Regeln
- Änderungen führen sofort zu einer Neubewertung der gesamten Datenstruktur
👉 Datenqualität ist damit kein nachgelagerter Prozess mehr, sondern eine Eigenschaft des Systems selbst.
👉 In der Praxis erfolgt dies durch Plausibilitätsprüfungen und eine regelbasierte Datenlogik im PIM.
So setzt Contene Produktdatenqualität konkret um
Genau hier setzt Contene an:
👉 Datenqualität entsteht nicht nachgelagert, sondern direkt im System – bei jeder Änderung, bei jeder Berechnung.
→ Wie Contene als System aufgebaut ist, erfahren Sie hier: Contene verstehen
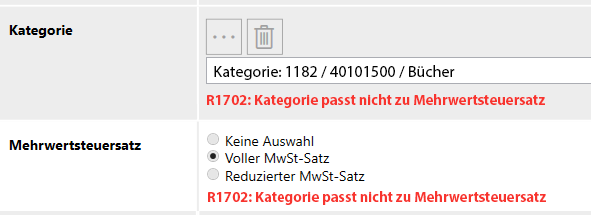
1. Plausibilitätsprüfungen (Crosschecks)
Contene erkennt Widersprüche sofort – zum Beispiel wenn Kategorie und steuerliche Angaben nicht zusammenpassen – und zeigt Fehler direkt im Datensatz an.
- Prüfungen laufen bei Eingabe und Verarbeitung
- Abhängigkeiten zwischen Attributen werden berücksichtigt
- Fehler verweisen direkt auf ihre Ursache
👉 Daten werden nicht kontrolliert, sondern systematisch validiert.
2. Decision Engine
Regeln werden in vertrauter Excel‑Logik definiert und in einer performanten Laufzeitumgebung ausgeführt. Typische Anwendungen: automatische Werte, Channel‑Readiness, Datenqualitäts‑Scores und automatische Stichwort‑Generierung. Fachabteilungen definieren Regeln selbst – ohne IT.
Typische Anwendungen sind:
- Bei der Neuanlage eines Datensatzes wird automatisch das Datum der Erstanlage hinterlegt,
- Erst wenn bestimmte Attribute mit Inhalten befüllt wurden, veröffentlicht das System automatisch den Artikel im Shopsystem (Channel‑Readiness)
- Formeln ermitteln je Artikel eine Punktzahl für Datenqualitäts‑Scores der Attibute. Der Contentmanager kann so gezielt nach Artikeln mit niedriger Punktzahl ermitteln und dort die Datenqualität erhöhen.
- Ausgehend von Kategorie und Technischen Eigenschaften werden automatische Stichwörter erzeugt
👉 Fachabteilungen definieren die Logik selbst – ohne IT.
Hier finden Sie Details zur Funktionsweise der Decision Engine in Contene.

3. Automatische Zustände statt manueller Pflege
Zustände wie „veröffentlichungsfähig“ oder „vollständig“ werden nicht manuell gesetzt.
Sie entstehen automatisch:
- aus Datenqualität
- aus Regeln
- aus Beziehungen zwischen Entitäten
👉 Ändert sich eine Voraussetzung, wird der Zustand sofort neu berechnet.
4. Datenqualität wird messbar
Durch Scores und Bewertungen wird Produktdatenqualität sichtbar:
- Artikel mit geringer Qualität werden gezielt identifiziert
- Maßnahmen lassen sich priorisieren
- Fortschritt wird nachvollziehbar
👉 Produktdatenqualität wird steuerbar – nicht nur überprüfbar.
5. Zusammenhang von Daten und Auffindbarkeit
Datenqualität wirkt sich direkt auf Auffindbarkeit und SEO aus.
Durch strukturierte Beziehungen und semantische Logik:
- entstehen automatisch konsistente Stichwörter
- vererben sich Änderungen über alle betroffenen Artikel
- bleibt der gesamte Datenbestand synchron
👉 Qualität und Auffindbarkeit werden gemeinsam optimiert.
Typische Beispiele für Probleme mit der Produktdatenqualität im PIM
Die folgenden Situationen treten in der Praxis besonders häufig auf:
- ein Produkt hat keine oder eine zu kurze Beschreibung
- ein Bild fehlt oder ist falsch zugeordnet
- regulatorische Angaben sind inkonsistent
- ein Artikel wird veröffentlicht, obwohl wichtige Informationen fehlen
- Daten aus ERP und PIM widersprechen sich
👉 Plausibilitätsprüfungen erkennen solche Probleme automatisch und verhindern, dass sie in den Webshop gelangen.
Wie Plausibilitätsprüfungen in der Praxis eingesetzt werden können Sie in den Anwendungsfällen für Plausibilitätsprüfungen nachlesen.
Ergebnis: bessere Daten, weniger Aufwand, höhere Conversion
Durch eine systematische Absicherung der Produktdatenqualität ergeben sich klare Vorteile:
- Produktdaten sind vollständig und konsistent
- Fehler werden frühzeitig erkannt und behoben
- manueller Prüfaufwand wird reduziert
- Produkte sind besser auffindbar und verständlicher
- die Conversion im Webshop verbessert sich
👉 Datenqualität wird damit vom manuellen Prozess zu einer steuerbaren Systemeigenschaft.
→ Wie sich das konkret auf die tägliche Arbeit auswirkt, zeigt die Produktivität im PIM
→ Warum selbst korrekte Daten im Shop trotzdem falsch erscheinen können, zeigt der PIM Output
Häufige Fragen zur Produktdatenqualität im PIM
Was ist Produktdatenqualität?
Der Zustand und die Verlässlichkeit aller produktbezogenen Informationen im PIM.
Warum ist Produktdatenqualität wichtig?
Weil sie direkten Einfluss auf Auffindbarkeit, Verständlichkeit und Conversion hat.
Wie lässt sich Produktdatenqualität im PIM verbessern?
Durch automatisierte Validierung, klare Regeln und eine systematische Entscheidungslogik.
Fazit
Produktdatenqualität im PIM entsteht nicht durch Kontrolle –
sondern durch klare Regeln, die automatisch für Konsistenz sorgen.
👉 Contene macht genau das möglich:
Daten werden nicht nur gepflegt, sondern systematisch berechnet, geprüft und gesteuert.